Hi,
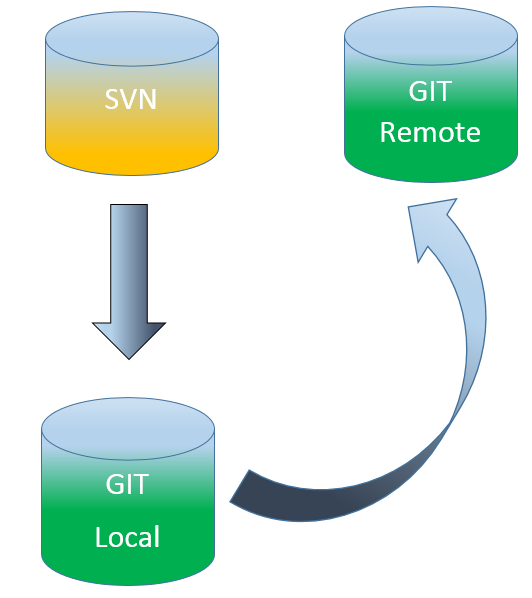
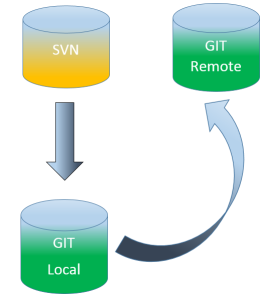
I have recently spent some time trying to migrate several SVN repositories to GIT. The tool that I used was called SVN2GIT and the detailed steps can be found below:
- Generate the authors.txt file.
- Copy the authors.txt file to your local .git folder.
- Open Command Prompt, navigate to your .git folder and run this command if your repo doesn’t follow the classic structure (/tags, /branches, /trunk):
svn2git <svn_repo_url> –rootistrunk –authors authors.txt

4. If your repo does follow the classic structure then you can choose to exclude the tags and branches folders to save time and disk space:
svn2git <svn_repo_url> –notags –nobranches –authors authors.txt

5. Go to the remote GIT server and create a new remote repository.
6. Then you need to configure GIT for the first time:
git config –global user.name “your name”
git config –global user.email “your email”

N.B.: The GIT repository should remain as read-only until the whole team switches to GIT for all the projects.
If multiple SVN commits are performed after the migration please follow these steps to easily synchronize both repos:
- Open Command Prompt
- Go to your local GIT repository.
- Run this command to import all the recent SVN commits into the local GIT repository:
svn2git –rebase
- Run this command to push all the changes to the remote repository:
git push origin master
Atlassian has its own tool of migration but it needs more steps than SVN2GIT to migrate a repo.
In the next part I will present several issues that were found during migration:
Issue 1: The XML Response contains invalid XML: malformed XML: no element found at /mingsv64/share/perl5/site_perl/git/ra.mp line 312.
Explanation: This issue usually occurs when dealing with very large repositories (like mine) and when this command is applied on the root directory:
svn2git <svn_repo_url> –notags –nobranches –authors authors.txt
After tens of thousands of revisions being migrated this process stops due to unknown issues.
Solution: Instead of going on the root directory and exclude the /branches and /tags folders we went straight to the /trunk folder and ran this command:
svn2git <svn_repo_url/trunk> –rootistrunk –authors authors.txt
Issue 2: Global .GITCONFIG file may be located on a shared network drive (H :\).
Explanation: If you’re using a client computer that runs inside their corporate network then this situation is very likely to occur.
Solution: Move the .GITCONFIG file from the network drive to your local drive and add this environment variable GIT_CONFIG that points to your local folder. If GIT_CONFIG is not working add the HOME environment variable instead.
- Moving the .GITCONFIG file to the C drive might cause permission restrictions. In this case move the config file to this location: C:\ProgramData\
- The local folder can be any folder of your choice. If there is only C: drive on the disk try and place it in here: C:\Program Files\Git\etc
- Check where .gitConfig file is located: git config –list –show-origin




 3. Create the intents using DialogFlow console – the intents can be found
3. Create the intents using DialogFlow console – the intents can be found